![]() When it comes to the blockchain, most people fall into one of two camps: the hand-wavers that think the blockchain will disrupt and benefit the world as profoundly as the Internet, and those who are scratching their heads and just can't see how that could be possible. I confess that I fall more into the second camp than the first, but I do recognize that blockchain technology can provide a far superior tool to tackle some challenges than any that we've had to work with before.
When it comes to the blockchain, most people fall into one of two camps: the hand-wavers that think the blockchain will disrupt and benefit the world as profoundly as the Internet, and those who are scratching their heads and just can't see how that could be possible. I confess that I fall more into the second camp than the first, but I do recognize that blockchain technology can provide a far superior tool to tackle some challenges than any that we've had to work with before.
I identified just such a challenge many years ago when the Internet was really taking off, and suggested that individuals needed to seize control of their personal information before commercial interests ran off with it instead, locking it away inside proprietary databases. The date of that article? February 2004, the same month that a little Web site called Facebook went live. Back then the problem was (and it still is) that the critical keys to avoiding data lock in are standards, and the process that develops those standards wasn't (and still isn't) controlled by end users.
Here's how I posed the challenge in that article:
“The Old Way: Do standards serve a useful purpose? Certainly, yes. But whose useful purpose do they serve? Consider these two questions and answers:
Q: Where do standards come from?
A: From the top.
Q: Who must live with the results?
A: Those at the bottom”
When it comes to data, standards are what gives a data owner the freedom to switch vendors and platforms. Absent standards, moving to another platform would be difficult or impossible. The absence of standards also sets the stage for “winner take all” situations where there is no choice.
Let’s turn back the clock again to that article, and what I saw might lie ahead:
[W]ith the evolution and popular adoption of the Web, the types and value of data that are being made available in digital form are expanding explosively. Managing that data is becoming an increasing challenge. Further, virtually all types of data important to one’s everyday existence are becoming digitized and are managed in that form: academic records, vehicle registrations, personal banking, and so on.
Ten years from now, one can only expect that this trend will have accelerated to a point where life will be impractical without seamless access to all imaginable types of data, anywhere, anytime. The importance of acquiring, securely maintaining and accessing that data therefore will become paramount. If we ever lost our data, we would be reduced to digital non-persons.
In short, we’ll all be drowning in data — pictures, music, documents, health data, employment data, and on and on and on. How will we organize it? Archive it? Access it? Maintain it from cradle to grave (and beyond?)
In the fourteen years since I issued this warning, things have turned out pretty much as I feared they might. Companies like Google, Amazon, Facebook, Twitter and others dominate their respective niches, each amassing enormous treasure troves of your and my data, all subject to only those permissions these companies choose to offer to us, usually buried deep within their sites.
Clearly, there is awareness now of the need for better privacy controls. But this camouflages a bigger issue, which is we don’t own or control our own data, almost all of which is in proprietary formats that prevent us from moving it even if there was somewhere to move it to.
Could there be a better way? And if so, what would it look like? Here’s how I presented it back in 2004:
A World of Virtual Spheres: In 1925, a French Jesuit geologist/paleontologist/philosopher named Pere Pierre Teilhard de Chardin wrote a seminal article visualizing a new layer of consciousness surrounding the globe, comprising all human thought and culture. Akin, in its own way to the biosphere or the atmosphere, Chardin called it the “Noosphere”. Years later, with the advent of the Internet and the Web, many found Chardin’s concept to be even more prescient and startlingly relevant.
In truth, we are increasingly living in a world of virtual, data-driven spheres. The Web, with its almost infinite possibilities, creates a universally accessible interconnection to all of the world’s knowledge that has been converted into digital form; business-owned spheres represented by myriad wide-area networks; governmental spheres assembled at the local, state and national levels; knowledge domain libraries created by universities.
And, I would propose, 6 billion “personal data spheres”.
What is a personal data sphere (PDS)? I posit that humanity is irreversibly entering an era in which every individual will be living his or her life within an ever more rich and dynamic PDS. An individual’s PDS will begin to be created before birth (e.g., prenatal medical records, parental estate planning documents, etc.), will accompany the individual throughout life, and in many respects will need to be accessible after death by the former owner’s estate, children, the genetic counselors of the former owner’s descendents, and so on.
The importance of enabling the easy maintenance, secure storage and ready access of the PDS will be an essential element of the human condition for the rest of foreseeable history. Accordingly, facilitating the creation and maintenance of the PDS needs to be given the same degree of respect and priority as business data spheres, government communication systems and the Internet.
As earlier noted, vendors have little incentive to coordinate the acquisition, management and access of diverse types of personal data. Accordingly, except to the extent that addressing these issues must be coordinated to serve the commercial interests of vendors, there is no incentive for traditional standard setting players to direct their efforts to optimize the ease of dealing with data of all types for the individual end user. Hence, the PDS will be enabled only as, and in such a way, as will serve the uncoordinated best interests of vendors. The result will assuredly be a hodge-podge of disparate interfaces, database structures and access protocols.
<snip>
Requirements of the PDS: In order to meet all needs, a PDS must at minimum enable:
- Easy input of all types of data now or in the future imaginable
- Easy organization of that data in an intuitive way
- Secure storage and backup
- Appropriate rights management and privacy protection, including with respect to government access
- Ready access from anywhere, at any time, through any currently available or future digital device
- Single sign on owner access to PDS information that is maintained by third parties (e.g., physicians, government, etc.)
- Seamless exchange with anyone granted appropriate rights, anywhere in the world
- Portability throughout the life of the owner
Needless to say, none of this has happened. But the move towards a data-drenched world in which we are more dependent on, and vulnerable to, the use of that data has, if anything, exceeded my expectations.
That’s the bad news. Here’s the good news: with the advent of the blockchain and the broad adoption of open source software (OSS) development, we now have a far more elegant and practical way to create and take control of our personal dataspheres. In principle, the blockchain provides a workable way for data to be stored and shared with no central repository authority. The question would be, how to go about it?
As it happens, there is at least once blockchain project in existence created for this express purpose. It’s called the Pillar Project, and you can find it’s website here. Partway down that page you’ll see a graphic that looks very much like the personal datasphere paradigm I described above. It looks like this:
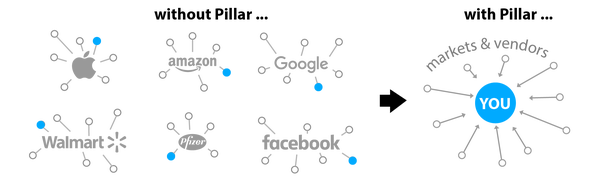
Clearly, that’s a vision that I can resonate with. The question is, will the Pillar Project succeed technically, and if it succeeds technically, will it succeed in the marketplace? That’s a question that does not yet have an answer. What are the odds?
It’s hard to tell, because there’s so little information at the site. It says that they completed an initial coin offering (ICO), but doesn’t say how much they raised. I couldn’t find a Pillar Project Wikipedia page, but I did find an article that expressed some reservations. Most concerning to me is the concept that there will be a wallet to hold both the Pillar alt coin as well as personal data, which seems to indicate at best mixed motivations underlying the technology. I would be far more impressed if there was no coin at all: transaction fees to my mind would be a healthier alternative that would allow the project to focus on information without the distraction of a fluctuating alt coin and speculation.
While I applaud their vision and wish them well, for now I’ll and I need to close this post with questions similar to those I ended with fourteen years ago:
Will we mount the support efforts like the Pillar Project in an effort to gain control over our own personal dataspheres? Or will we allow the commercial marketplace to continue to collect, mine, control and restrict our access to our own data?
The answer to that question will determine whether we remain hostage to the whims and best interests of huge companies, or – for the first time – become masters of our own data destiny.